Notre approche du Textmining
Les données web constituent un univers sans limites et un formidable terrain d’études & recherches. Aujourd’hui, les données textuelles font partie intégrante de ce que d’aucuns appellent le « Big Data ». Des avancées dans la visualisation des statistiques lexicales sont notables associant fréquence et co-occurrence.
PCW-Etudes suit l’évolution de la recherche en textmining, notamment en participant aux séminaires des universités (Centre d’étude des discours, images, textes, écrits, communication Créteil Val de Marne) et en contribuant au programme de recherches IMAGIWEB (Laboratoire ERIC Lyon 2 http://mediamining.univ-lyon2.fr/people/velcin//imagiweb/).
La mutualisation de la fonctionnalité des outils
Cette veille en matière de recherche ainsi que notre expérience auprès de nos clients nous a permis de développer une méthode d’analyse fine qui allie l’utilisation conjointe de plusieurs logiciels de fouille de texte et l’expertise sémio-linguistique.

Capture Ecran du logiciel TreeCloud sur la base d’un corpus de commentaires Deezer
Le logiciel TreeCloud permet de générer des nuages arborés à partir d'un texte, autrement dit des nuages de mots par fréquence et disposés autour de branches qui indiquent leur proximité dans le texte (co-occurrence). Cet outil de visualisation a été conçu par Philippe Gambette (Laboratoire d’informatique LIGM Marne la Vallée UMR 8049) à partir du concept de visualisation proposé par Jean Véronis.
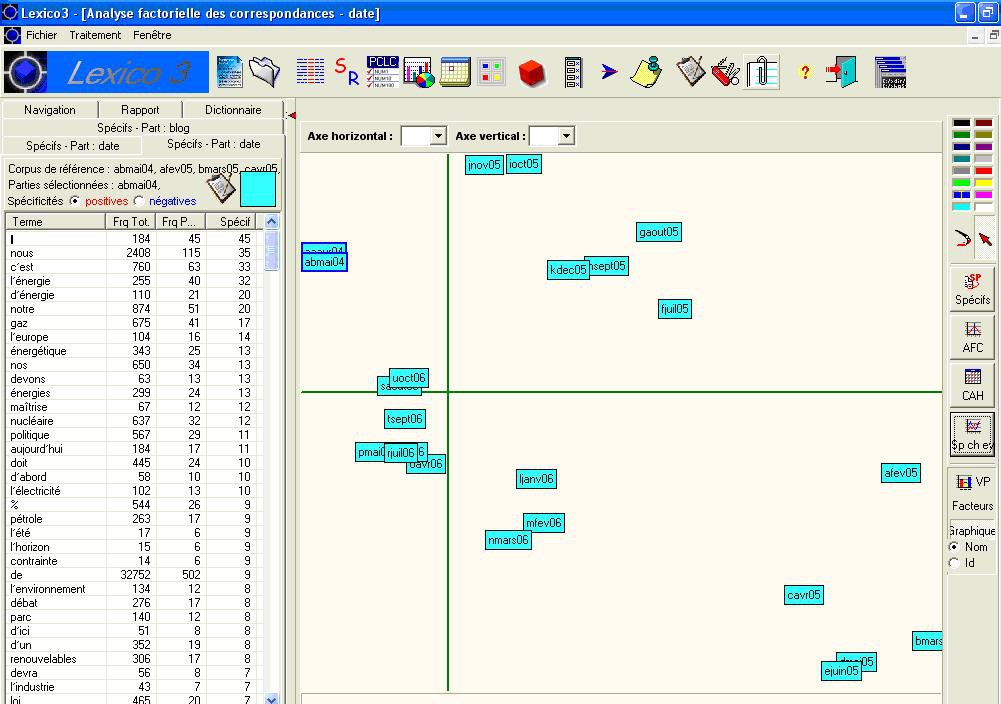
Capture Ecran d’un résultat d’analyse factorielle générée par Lexico3 sur la base d’un corpus de Blogs
Le logiciel Lexico 3 permet de repérer le vocabulaire utilisé en restituant la fréquence du lexique et son contexte immédiat. L’intérêt du logiciel est d’identifier les spécificités lexicales d’un corpus par rapport à un autre via un calcul de probabilité (coefficient de spécificité ou non spécificité). Lexico 3 est un logiciel conçu pour le traitement lexicométrique de textes volumineux. Il est développé par le laboratoire CLA2T SYLED de l’Université de la Sorbonne Nouvelle
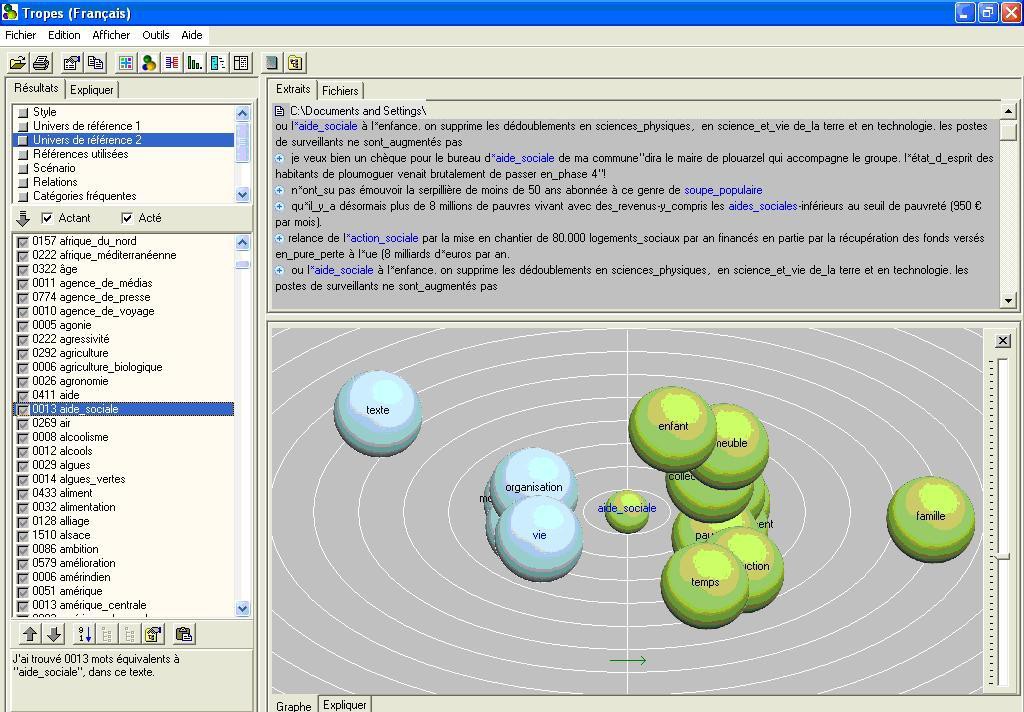
Visualisation avec Tropes des proximités des Références (classe d’équivalents) autour de l’occurrence « aide sociale » dans les titres d’un corpus de blogs- avant (en bleu) et après (en vert) l’occurrence «aide sociale ».
En complémentarité de ces deux logiciels, Tropes utilise des techniques de classification sémantique (classe d’équivalents / désambigüisation) et de génération de thesaurus. Ce logiciel permet notamment de classifier le corpus étudié sur la base d’ontologies et de catégoriser grammaticalement les occurrences. Tropes est un logiciel développé par Pierre Molette et Agnès Landré sur la base des travaux de Rodolphe Ghiglione.
à Ces différents outils permettent de construire des sous échantillons pertinents pour l’analyse. L’approche sémio-linguistique appréhende ensuite ces échantillons dans leur linéarité discursive en analysant plus finement les représentations à l’œuvre dans les discours et en mettant en évidence les thèmes, opinions exprimées et modalités d’énonciation.
Lien permanent
Catégories : b. NOTRE APPROCHE DU TEXTMINING